时间:2023.1
作者:John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, Tom Goldstein
会议:ICML’23
大型语言模型可能产生的潜在危害可以通过在生成的文本中嵌入水印来降低,即在文本片段中的一小段连续词汇中嵌入难以被人眼察觉但可以通过算法探测的信号。我们提出了一种水印框架,用于专有的语言模型。水印可以嵌入文本中而几乎不影响文本质量,并且可以使用开源算法进行检测,而不需要访问语言模型的API或参数。此水印通过在生成词汇前选择一组随机的”绿色”词汇,并在取样过程中轻微地提高这些”绿色”词汇的使用概率来实现。我们提出了一种统计检验方法来检测水印,该方法可以给出容易解释的P值,并给出了分析水印敏感性的信息论框架。我们在OPT家族的多亿参数模型上测试了该水印,并讨论了其鲁棒性和安全性。
基础知识
语言生成模型的基本原理是:
- 输入一个样本词序列(可以是空的),比如”春风拂人面”。
- 模型内部含有一个巨大的词汇表,词汇表包含了所有可能出现的词语。
- 模型根据输入词序列,计算每个词汇表内词语出现的概率,形成一个概率分布。通常使用栈式长短期记忆网络(LSTM)来提取词序列上下文信息,然后计算每个词的条件概率。
- 根据这个概率分布随机采样获得下一个词。比如”吹”的概率最大,就随机选择”吹”作为下一个词。
- 把这个新词加入输入序列,执行3-4步,不断扩展序列。
- 通过反复扩展序列,可以自动生成与输入样本风格相似的新句子,像人类一样进行语言产出。
- 随着模型规模越来越大,训练数据量也越来越大,生成效果不断提高,产生出来的句子质量和人类语言越来越相似。
- 但模型内部机制是统计规律,理解能力有限,可能会出现不合逻辑或不正确的情景。所以语言生成只能助于创作,但不等同于真正的语言理解。
以上就是语言生成模型的基本思路和工作流程。它通过统计连续词汇的条件概率来模拟人类语言产出的过程。
文本熵是用来衡量文本随机性程度的一个量度
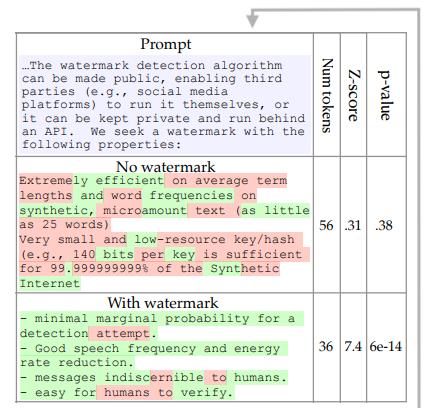
- Figure 1给出了带有水印和无水印的语言模型生成文本示例。
- 无水印文本采用了整个提示段落(用蓝色标注)作为输入。
- 带水印文本使用相同提示,但应用了水印技术。
- 水印技术会给部分词汇赋予“绿色”标签(如图中的绿色词汇)。
- 检测结果显示,带水印文本生成的“绿色”词汇远超预期值(28个比预期9个多很多)。
- 以此计算得出的p值非常小(约6×10-14),证明这绝非随机产生,而很可能来自受水印影响的模型。
- 说明通过统计检测可以很高概率判断带水印文本是否来源于该语言模型。
- 同时给出了水印参数γ和δ,以供后续实验参考。
- 利用了OPT-6.7B模型和多项式抽样进行实验。
红单水印机制
思路:
- 考虑到单词水印可能被分词工具破坏,采用短语概率进行水印编码
- 事先选择一组短语作为水印载体,将其概率提高来生成水印文本
主要流程:
- 从语料库中采样获取一组长度为k的短语序列作为水印载体
- 输入语料和诱导前缀,使用 n-gram LM模型计算每个可能短语的概率分布
- 将水印载体短语的概率提高一个比例因子(1+γ)
- 根据修改后的概率分布采样选择下一个短语加入水印文本
- 重复上述步骤生成完整水印文本

检测过程:
- 统计检测文本中的水印载体短语出现次数Nc
- 根据 texts长度L和装载体短语总数C,计算期望值E(Nc)
- 用超额比对Nc和E(Nc),计算p值判断是否含水印
算法二的改进在于利用短语概率而非单词概率进行水印编码,使水印更难被破坏,同时检测方法与算法一相似。